
Browser and device fingerprinting have become critical tools for online security. This advanced technique enables websites to identify and track users based on their unique device and browser characteristics. SecureAuth is at the forefront of this technology, offering state-of-the-art Identity and Access Management (IAM) solutions that leverage the latest developments in browser and device fingerprinting to enhance security and user experience.
What is Browser and Device Fingerprinting?
Browser and device fingerprinting involve collecting various data points from a user’s device and browser to create a unique identifier. These data points include:
- Browser Type and Version: Information about the browser being used.
- Operating System: The device’s operating system.
- Screen Resolution: The screen’s size and resolution.
- Installed Plugins and Fonts: Details of installed browser plugins and system fonts.
- Time Zone and Language Settings: Local settings that can help in identifying the user.
By aggregating these data points, websites can generate a fingerprint that is unique to each user, making it possible to track and identify them across sessions and even different websites.
The Evolution of Browser and Device Fingerprinting
The technique of browser fingerprinting has evolved significantly over the years. Initially used for basic user identification, it has now become a sophisticated method of enhancing online security. Recent studies highlight the growing accuracy and reliability of browser fingerprinting:
- Increased Accuracy: Modern fingerprinting methods can achieve higher precision by incorporating more data points and advanced algorithms. Research by Vasilios Mavroudis and his team at University College London demonstrated that combining multiple fingerprinting techniques can improve identification accuracy (Mavroudis et al., 2021).
- Machine Learning Integration: Recent advancements have seen the integration of machine learning to predict and identify changes in device configurations, making fingerprinting more resilient to user modifications (Al-Fannah et al., 2022).
- Cross-Browser Fingerprinting: Innovations have enabled cross-browser fingerprinting, allowing for user identification across different browsers on the same device. This technique, explored by Gómez-Boix et al. (2021), enhances tracking capabilities significantly.
Security Implications of Browser and Device Fingerprinting
Browser and device fingerprinting have profound implications for online security:
- Enhanced Fraud Detection: By identifying users accurately, fingerprinting helps detect and prevent fraudulent activities. For example, if a login attempt is made from a new or altered fingerprint, it can trigger additional security measures.
- Account Takeover Protection: Fingerprinting can detect unusual device configurations or browser settings, indicating potential account takeover attempts.
- Improved User Experience: SecureAuth’s IAM solutions utilize fingerprinting to streamline authentication processes, reducing the need for repetitive multi-factor authentication (MFA) challenges for recognized devices.
Ethical Considerations and Privacy Concerns
While fingerprinting offers significant security benefits, it also raises privacy concerns. The ability to track users without their explicit consent can be seen as invasive. To address these concerns, SecureAuth emphasizes the importance of transparency and user consent in fingerprinting practices. Recent legislation, such as the General Data Protection Regulation (GDPR), underscores the need for ethical data handling and user privacy protection.
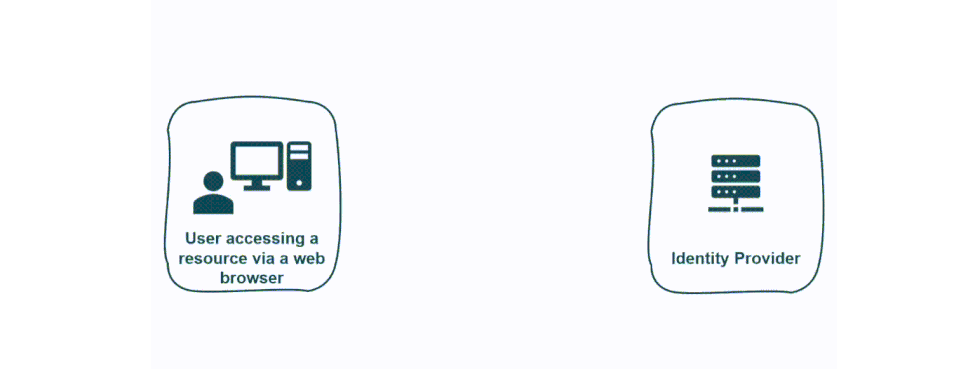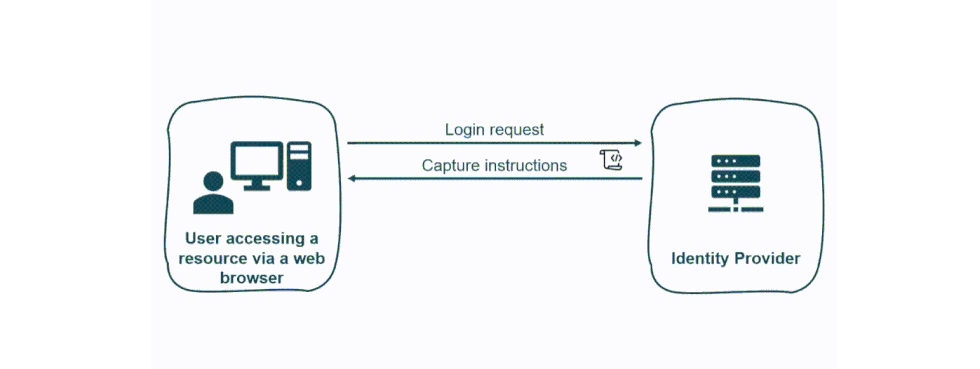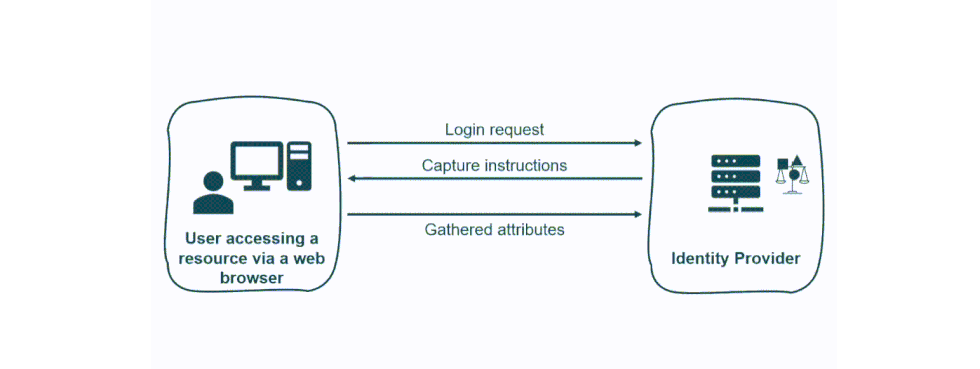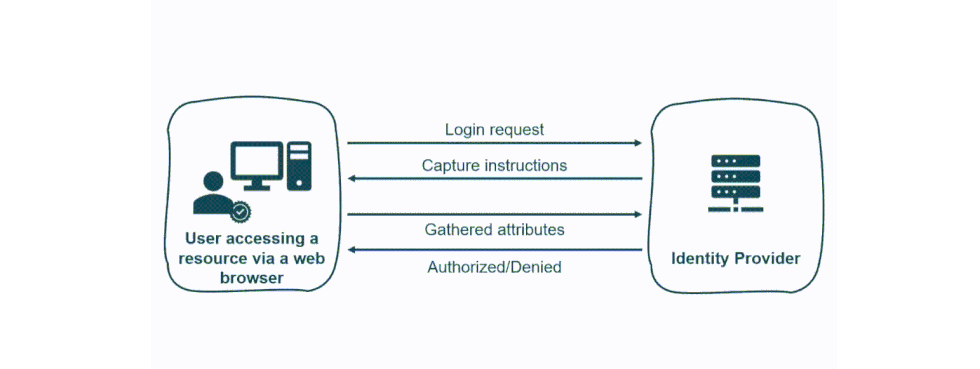
Strategy to Win the Arms Race
We can follow two approaches to identify a browser. One consists in obtaining a fingerprint hash from a set of entropy sources. While the other consists in a heuristic-based method that includes browser fingerprints variables (both in the context of a Continuous Authentication or a Multi Factor Authentication model). The first tactic should group those fingerprints with the highest level of entropy to obtain a more unique hash. While, in the heuristic approach, we can define a set of fingerprint elements tied to a variable score that allows the administrator to use a reasonable threshold to trigger actions. Using only BF for authentication is challenging. Attributes in a fingerprint can be captured, manipulated, and replayed, opening the doors to many different attacks on the web.
Why should we periodically update the fingerprinting method?
In our research we see that BF changes constantly over time due to updates in browsers, changes in user settings or changes in the user systems/devices. For that reason, we consider two main points to address stability. On the one hand, we need to keep the fingerprint techniques updated considering the main browsers release cycles. Each main browser has a release process, for example, Firefox has new major releases on four-week cycles and Chrome is updated every two to three weeks for minor releases and every six weeks for major releases. We should track changes in short periods of time to see if there are any variations in what we are doing and if we are losing effectiveness in the methods we have chosen. As we will see in this article, not all the methods affect the effectiveness in the same way. On the other hand, we should keep in mind that the user fingerprints could vary faster than the browser changes, that translates in the adequation of the authentication strategy accordingly (e.g., use fingerprints with an expired date or, in a heuristic model, decrease its weight as time passes).
Consequently, we could leverage the fingerprint for a few days (weeks perhaps for users that do not travel and less for users that travel frequently) as another authentication factor to reduce the friction with the user. While, in the background we should always run the automated tests to see if something in the browser changed. Furthermore, we could enforce the use of cookies and Java scripts APIs to be able to properly fingerprint the user’s browser.
How uniquely identifiable are fingerprints in our data sets?
We must determine how diverse/unique the browser fingerprints are according to each method. Recall that a fingerprint is unique since it has an attribute whose value is only present once in the whole dataset or, because the combination of all its attributes is unique in the whole dataset.
Being able to uniquely identify users’ fingerprints in the IAM industry makes the difference when the fingerprint is used as another authentication factor since it would be difficult to tamper a fingerprint and re-use it, and therefore, unique fingerprints boost the security of our systems and leverage a frictionless experience.
Then the next question that arises is: how can we measure this uniqueness? We evaluate this through distance and entropy. The first concept relates to the similarity of all the attributes of one user’s fingerprint to another user’s fingerprint, and even between its own fingerprints. This tells us how a device-browser fingerprint relates to another. If the similarity is zero, the distance between fingerprints is equal to one, so those fingerprints are far from each other and more identifiable. The second concept is used to quantify the level of informational value in a fingerprint, the higher the entropy, the more unique and identifiable the fingerprint is. For measuring entropy, we use the Shannon’s formula.
Nevertheless, how can we validate that the entropy is because of real changes in the browser or aleatory ones due to anti-fingerprint measures? We need to make sure that the fingerprints have some sort of stability. We can analyze this by storing the fingerprints and evaluating their changes over time. Moreover, having this type of information leads us to know when and why we should update the fingerprint methods.
Going to the facts
If we want to keep our experiences frictionless and secure, we need a plan to keep the methods updated and real data! During the past months we have been gathering information in-company about our fingerprints, and we want to share with you some of the results. We have collected 209 fingerprints from peers that volunteered for our DFP update project throughout 20 working days.
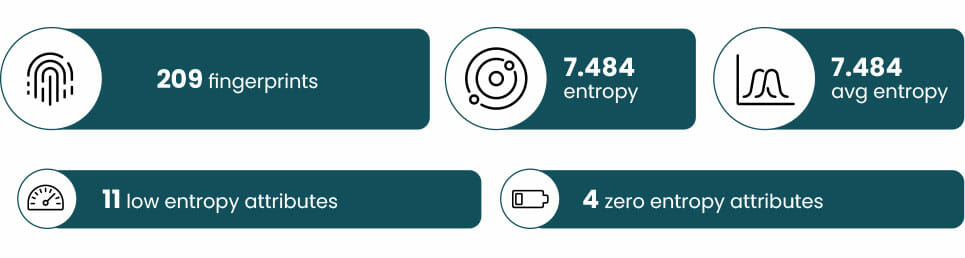
Although entropy results change with the number of fingerprints collected, we can have a general idea of what is happening, and that’s enough to make some decisions. For example, if we have some zero entropy attributes, which means that all the fingerprints have the same value for them. Therefore, we could remove these attributes since they are not adding real worth. Moreover, low-level entropy attributes, as in the previous case, are attributes that do not contribute with the fingerprint uniqueness. It would be interesting to define a minimum level of entropy that the attributes must reach to be included in the fingerprinting method.
Another way to see the uniqueness of the fingerprints is to check the similarity of all the attributes of one user’s fingerprint to another user’s fingerprint, and between its own fingerprints. These correlations give us an idea of the similarity between the fingerprints and, therefore, the ability of the algorithm to differentiate them.
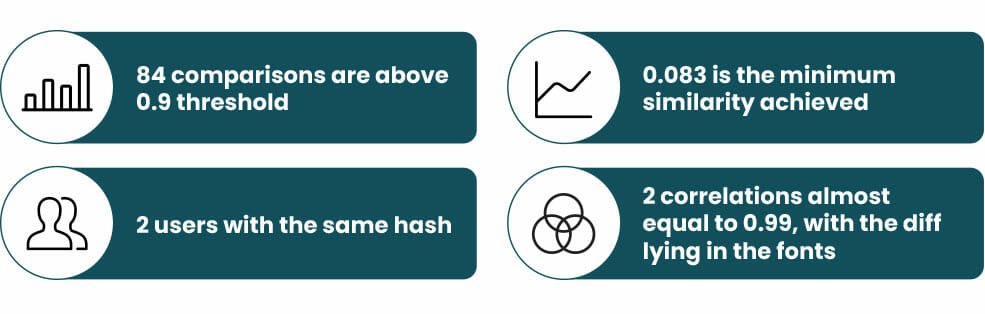
From 6105 correlations, only 84 results are above the 0.9 threshold used to consider that the fingerprint is similar enough to not ask for the second factor authentication. From these 84 correlations, only one has the same hash and two correlations are 0.99 similar, the difference between them lie in the fonts installed. If they are almost equal, does it mean our algorithm failed? No, this phenomenon is due to recently hired employees who just received a brand-new computer configured in the same way by the company.
The final interesting data is that the minimum similarity achieved between fingerprints is 0.083. It’s important to note that our data is not yet large enough to obtain definitive conclusions on the similarity and, as we reviewed in the literature, all fingerprint methods tend to have a considerable set of duplicates, so it wouldn’t be weird to have more collisions.
Now that we have seen how unique the fingerprints are, let’s see the most important part: the stability of the attributes. For this, we have mapped the fingerprints of each user through the time that the tests lasted. We have stored all the fingerprints in a database, matching them with a parent, i.e., the fingerprint that was most similar above a set threshold, from which we consider that the fingerprint is a derived version of the parent.
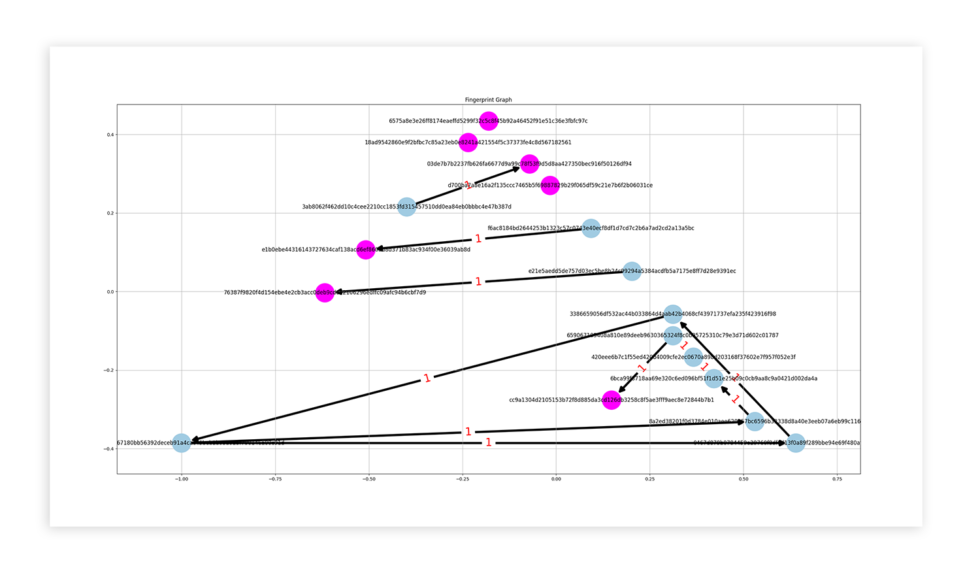
Figure 1: User X data, fingerprints evolution
By plotting the results of a user, we can see the evolution of the fingerprints. In Fig. 1, we see in magenta the fingerprints that are active (recognized as in use), while in blue those that are inactive. The labels are the fingerprint Id, i.e., the hash. The transitions may repeat if we encounter a nonstable attribute, for that reason we tag with the number of times the fingerprint has passed through that change. The scale has no significance at all, lines are drawn to not cross over for clarity.
Zooming in the results and leaving only the fingerprints that suffered change, we obtain the following table, where we can see how the attributes evolved from a fingerprint to another, and the similarity with the parent.
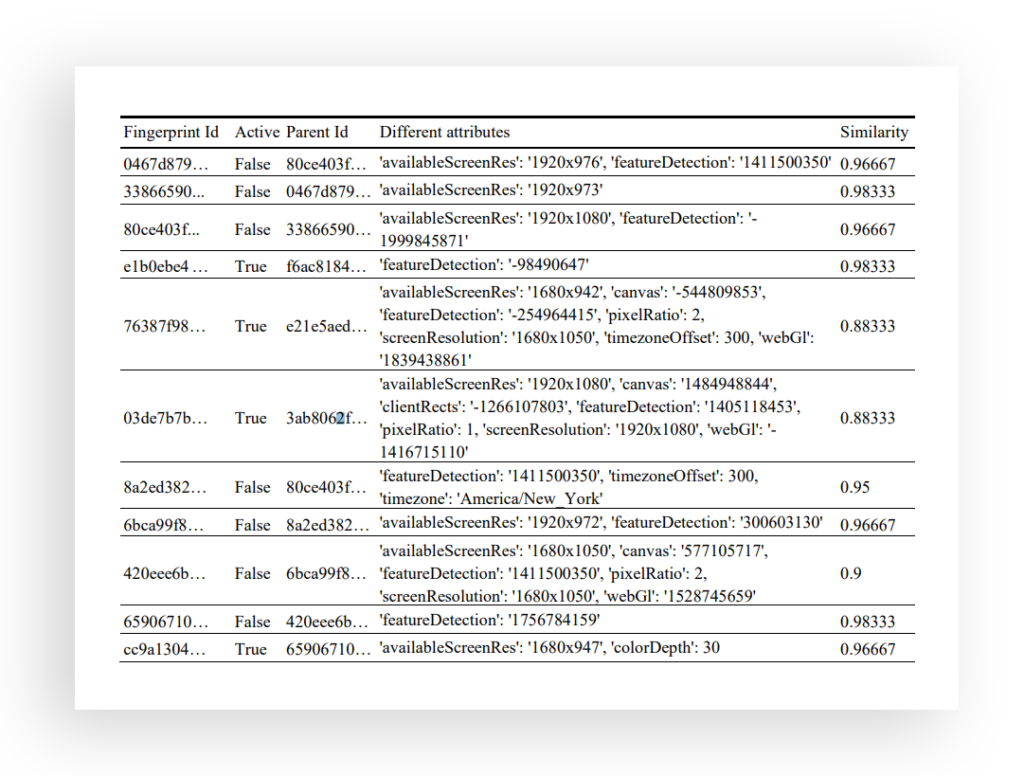
Figure 2: User X data, fingerprints evolution information
Note that the similarity is the score obtained by comparing each one of the attributes taken from the browser and summing them when they are equal. We have seized over 29 different attributes with our algorithm. We observe that the main changes between parent and child fingerprints are related to the screen resolution. These changes are very common between our users since they usually use laptops and a second screen monitor.
In addition, we spot feature Detection as one of the most volatile attributes. Nevertheless, we must consider that this technique involves dozens of tests to detect browser features and can be modified to gain stability. Moreover, we were able to corroborate that the changes in time zone and other attributes related to it, were due to a traveler volunteer.
Final thoughts
Through this research, we have been able to study in depth the importance of the attributes, when it comes to using these fingerprints as an authentication factor, as attributes are not equally consequential. Moreover, what will determine if we win the arms race with browsers, will be our ability to prepare our system for future changes to come and to have a clear path to constantly sample the fingerprinting algorithms.
Finally, the greatest impact on the insight can only be obtained by accessing real information and by asking the users involved in the tests about the attributes. This is what corroborates the changes in BFs algorithms, opposed to most of the literature found about browser fingerprinting, which is very rich and extensive, but lacks the validation of the real behavior of the users.
Leading the Way in Browser and Device Fingerprinting
SecureAuth is committed to leveraging the latest advancements in browser and device fingerprinting to enhance security while maintaining user trust and privacy. Our IAM solutions incorporate cutting-edge fingerprinting technology to provide robust protection against cyber threats. By continuously updating our methodologies and integrating the latest research findings, SecureAuth ensures that our clients benefit from the most effective and reliable security measures available.
Contact us to learn more about how SecureAuth’s IAM solutions support the latest device and browser fingerprinting.
References
Mavroudis, V., et al. (2021). “Combining Fingerprinting Techniques for Enhanced Accuracy.” University College London.
Al-Fannah, H., et al. (2022). “Machine Learning in Browser Fingerprinting.” Journal of Cybersecurity.
Gómez-Boix, A., et al. (2021). “Cross-Browser Fingerprinting: Enhancements and Implications.” Security and Privacy Journal.